How ChatGPT memory works, reverse engineered
Written by James Berry • Last updated December 13, 2025
I expected ChatGPT to use sophisticated retrieval systems to remember users. Turns out, the architecture is much simpler. Four layers working together create the illusion that ChatGPT knows you personally.
When ChatGPT remembers your name or references something you mentioned weeks ago, it feels like magic. The assistant seems to genuinely know you. But what is actually happening behind the scenes?
What is ChatGPT Memory
ChatGPT Memory is a personalization feature switched on by default for all users. Manthan Gupta ran a series of experiments to reverse engineer how ChatGPT stores and retrieves information. His findings surprised me. There are no complex vector databases. No retrieval-augmented generation searching through your conversation history. Instead, OpenAI built something far more practical.
I think this discovery matters for anyone trying to understand how AI systems work. The simplicity of the architecture tells us something about how OpenAI thinks about personalization at scale.
The Four Layers of Memory
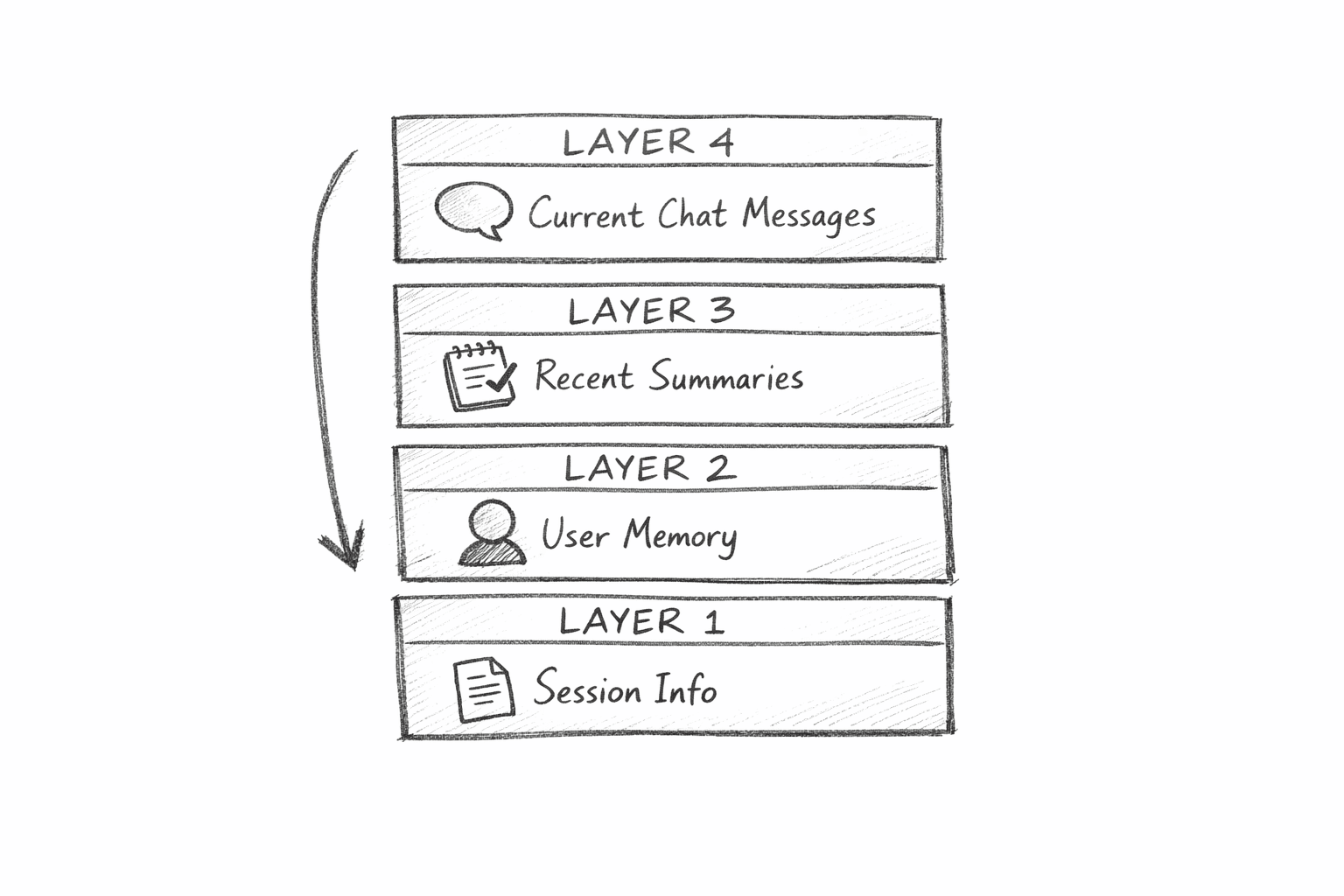
Every time you send a message to ChatGPT, it receives a structured context window. Understanding what goes into that window reveals how memory actually works.
The context window is everything the AI can see when generating a response. Think of it as ChatGPT's working memory. It has a fixed size, so OpenAI has to be selective about what goes in.
Here is what ChatGPT sees for each message, in order:
- System Instructions. Rules that define how ChatGPT should behave
- Developer Instructions. Additional configuration from the app or interface
- Session Metadata. Temporary details about your current environment
- User Memory. Permanent facts stored about you
- Recent Conversations Summary. Brief notes from your past chats
- Current Session Messages. Everything said in this conversation so far
The first two are not really memory. They tell ChatGPT how to act. The interesting parts start at layer three.
1. Session Metadata
When you start a new chat, ChatGPT receives a snapshot of your current environment. This information disappears when the session ends. It is not saved anywhere.
What kind of details does this include?
- Whether you are on desktop or mobile
- Your browser and operating system
- Your approximate location and timezone
- Your subscription tier
- How often you use ChatGPT
- Which models you typically use
- Your screen size and display settings
Here is what a session metadata block might look like:
- Subscription: ChatGPT Plus
- Device: Desktop browser
- Browser: Safari on macOS
- Location: United Kingdom
- Local time: 14:30
- Account age: 52 weeks
- Activity: Used 6 of the last 7 days
- Average messages per conversation: 12
- Model usage: 60% GPT-4o, 30% GPT-4o-mini, 10% o1
This explains why ChatGPT sometimes adapts to your environment. It knows you are on mobile, so it might write shorter responses. It knows your timezone, so it can reference "this morning" accurately.
I find this layer fascinating from an AI search perspective. ChatGPT is already personalizing responses based on who you are. Not just what you ask, but how you ask it, where you are, and what device you use.
2. User Memory
This is the layer most people think of when they hear "ChatGPT memory." These are permanent facts that persist across all your conversations.
Manthan discovered ChatGPT had stored 33 facts about him. Things like:
- His name and age
- Career goals and work history
- Current projects he is building
- Topics he is studying
- His fitness routine
- Personal preferences
How do facts get stored here? Two ways:
- You explicitly tell ChatGPT to remember something ("Remember that I prefer Python over JavaScript")
- ChatGPT detects something important (like your name or job) and you confirm it through natural conversation
You can also ask ChatGPT to forget things. Just say "delete this from memory" and it will remove the fact.
What I find interesting here is that this is not automatic learning. ChatGPT does not secretly build a profile by analyzing everything you say. The storage is deliberate. You either request it or confirm it. This is why AI share buttons are so effecitve for building your AI search visibility.
This matters for content creators thinking about AI personalization. If ChatGPT only stores explicit facts, then brand preferences and product knowledge would need to be stated directly by users. There is no hidden profiling happening based on what websites ChatGPT visits on your behalf.
3. Recent Conversations Summary
This layer surprised Manthan the most. I was also surprised when I read his findings.
Many AI systems use something called RAG (retrieval-augmented generation) to recall past information. RAG works by embedding all your past messages into a searchable database. When you ask a question, the system searches that database for relevant context.
ChatGPT does not do this. Instead, it keeps a lightweight list of recent conversation summaries. The format looks something like this:
1. Dec 8, 2025: "Building a load balancer in Go"
- asked about connection pooling
- discussed health check intervals
2. Dec 7, 2025: "Fitness routine optimization"
- wanted advice on recovery days
- asked about protein timing
A few observations from Manthan's research:
- ChatGPT only summarizes what you said, not its own responses
- There were about 15 recent conversations in the summary
- The summaries are brief. Just enough to remind ChatGPT what you were interested in.
Why does this matter? This approach trades depth for speed. Traditional RAG systems would need to search through thousands of messages, rank them by relevance, and inject the best matches into context. That takes time and tokens.
ChatGPT's approach skips the search step entirely. It pre-computes summaries and injects them directly. You get continuity across conversations without the latency hit.
For anyone building AI applications, this is a useful design pattern. Sometimes a simple summary beats a complex retrieval system.
4. Current Session Messages
This is the simplest layer. It is just the full transcript of your current conversation.
ChatGPT keeps everything you have said in this session. No summarization. No compression. Just the raw messages, exactly as you typed them.
There is a limit based on token count. Once you hit that limit, older messages in the current session start dropping off. But your stored facts and conversation summaries remain. The system prioritizes what it thinks you will need most.
This is what allows ChatGPT to follow complex multi-turn reasoning within a single chat. It has full context of everything said so far.
How The Layers Work Together
When you send a message, here is what ChatGPT actually receives:
First, it gets session metadata. This tells it about your device, location, and usage patterns. Injected once at the start of the session.
Second, it gets your stored facts. All 33 of them (or however many you have). These appear in every single message, ensuring ChatGPT always knows your preferences.
Third, it gets conversation summaries. A quick reminder of what you have been interested in lately.
Fourth, it gets the current conversation. Everything said in this chat so far.
Finally, it gets your actual message.
All of this fits within the token budget. When space runs low, the current session messages get trimmed first. Your permanent facts and recent summaries stay.
What This Means For AI Search
I spend a lot of time thinking about how AI systems find and cite content. This memory architecture reveals something important about how ChatGPT prioritizes information.
Personalization is already happening
ChatGPT is not giving everyone the same answers. It knows your location, your usage patterns, your stated preferences. Two users asking the same question might get different responses based on their stored facts and session context.
For content creators, this raises a question. If ChatGPT knows a user prefers a certain brand or has a specific background, does that influence which sources it cites? We do not know for certain, but the infrastructure is there.
Simple beats complex
Many AI engineers assumed ChatGPT would need sophisticated retrieval systems to feel personal. It does not. Four straightforward layers, each serving a specific purpose, create the experience of an assistant that remembers you.
This matches what we see elsewhere in ChatGPT's design. When we analyzed how ChatGPT reads web content, we found it uses a simple sliding window rather than reading entire pages. When we discovered OpenAI's cached search index, we found lightweight caching rather than complex real-time retrieval.
The pattern is consistent. OpenAI builds systems that are fast and efficient, even if they sacrifice some depth. For most use cases, that is the right trade-off.
Memory is explicit, not inferred
ChatGPT does not secretly learn your preferences by analyzing your browsing or reading between the lines. Memory storage is deliberate. You either ask for it or confirm it.
This is good news for privacy. But it also means ChatGPT's knowledge of users is shallow compared to what it could be. The system knows what you tell it, not what it observes.
The token budget shapes everything
Every layer competes for space in the context window. OpenAI chose to prioritize permanent facts and recent summaries over current session history. When you hit the limit, recent messages get trimmed, but your stored profile stays.
This tells us what OpenAI thinks matters most. Long-term personalization wins over short-term context.
ChatGPT Memories Takeaways
If you are trying to get your content cited by ChatGPT, this memory research does not change the fundamentals. You still need to be discoverable in search results, write parseable content that ChatGPT can read in chunks, and get ensure your content is crawlable by AI.
But it does add nuance. ChatGPT's responses are personalized. The user asking the question brings their own context. Their location, their preferences, their recent interests all influence what ChatGPT decides to include in its answer.
We cannot control user context. But we can write content that works for diverse audiences. Clear structure, specific facts, and direct answers help ensure your content gets cited regardless of who is asking.
Related Posts

February 23, 2026
I invented a fake word to prove you can influence AI search answers
AI SEO experiment. I made up the word "glimmergraftorium". Days later, ChatGPT confidently cited my definition as fact. Here is how to influence AI answers.

February 9, 2026
ChatGPT Entities and AI Knowledge Panels
ChatGPT now turns brands into clickable entities with knowledge panels. Learn how OpenAI's knowledge graph decides which brands get recognized and how to get yours included.

February 5, 2026
What are zero-click searches? How AI stole your traffic
Over 80% of searches in 2026 end without a click. Users get answers from AI Overviews or skip Google for ChatGPT. Learn what zero-click means and why CTR metrics no longer work.

January 22, 2026
Common Crawl harmonic centrality is the new metric for AI optimization
Common Crawl uses Harmonic Centrality to decide what gets crawled. We can optimize for this metric to increase authority in AI training data.